盗版小说网站下载离线小说方法
概述:
1 | 相信大家很多人都喜欢看小说,lures也不例外,lures高二的时候意外看到了《全职法师》,上了大学有时间也会看小说,今天就来给广大的朋友们分享一下如何在盗版小说网站上下载小说吧! |
1、前提准备:
1 | 1、电脑装有Python编译环境 |
2 | 2、Python编译器(IDLE/Pycharm/Geany/ipython.....) |
3 | 3、装有requests,re库 |
4 | 4、能上网 |
2、测试代码:
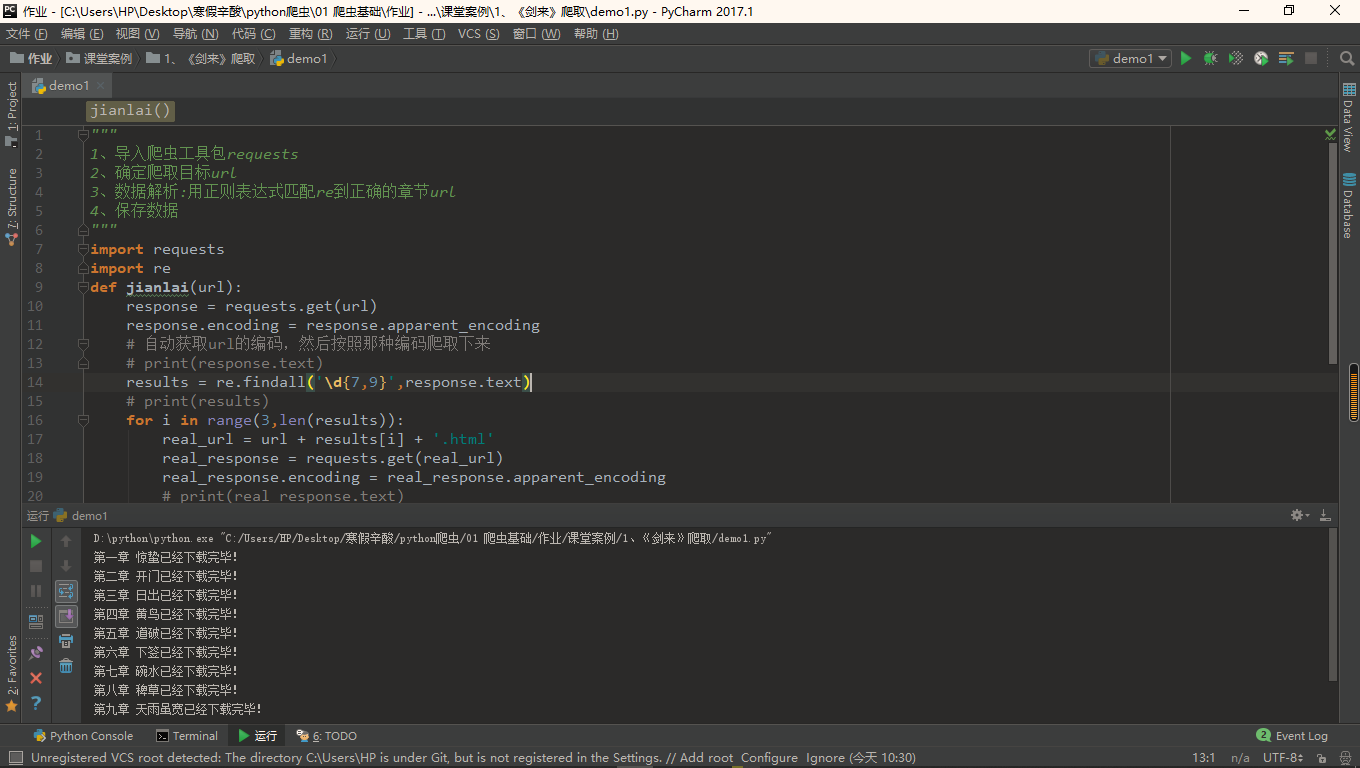
1 | """ |
2 | 1、导入爬虫工具包requests |
3 | 2、确定爬取目标url |
4 | 3、数据解析:用正则表达式匹配re到正确的章节url |
5 | 4、保存数据 |
6 | """ |
7 | import requests |
8 | import re |
9 | def jianlai(url): |
10 | response = requests.get(url) |
11 | response.encoding = response.apparent_encoding |
12 | # 自动获取url的编码,然后按照那种编码爬取下来 |
13 | # print(response.text) |
14 | results = re.findall('\d{7,9}',response.text) |
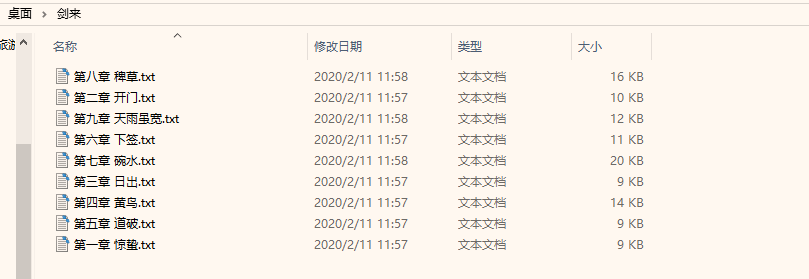
15 | # print(results) |
16 | for i in range(3,len(results)): |
17 | real_url = url + results[i] + '.html' |
18 | real_response = requests.get(real_url) |
19 | real_response.encoding = real_response.apparent_encoding |
20 | # print(real_response.text) |
21 | html = str(re.findall(' (.*?)<br />',real_response.text)) |
22 | name = (re.findall('<h1>(.*?)</h1>',real_response.text))[0] |
23 | with open('C:/Users/HP/Desktop/剑来/'+str(name)+'.txt','w',encoding="utf-8") as f: |
24 | f.write(str(html)) |
25 | print(str(name)+'已经下载完毕!') |
26 | f.close() |
27 | jianlai('https://www.xbiquge.cc/book/13810/') |
1 | """ |
2 | 1、导入爬虫工具包requests |
3 | 2、确定爬取目标url |
4 | 3、数据解析:用正则表达式匹配re到正确的章节url |
5 | 4、保存数据 |
6 | """ |
7 | import requests |
8 | import re |
9 | |
10 | # url = 'http://www.shuquge.com/txt/8659/index.html' |
11 | def shuquge_novel_download(url): |
12 | response = requests.get(url) |
13 | response.encoding = response.apparent_encoding |
14 | result = re.findall('<dd><a href="(.*?)">(.*?)</a></dd>', response.text, re.S) |
15 | # print(result) |
16 | for url, name in result: |
17 | new_url = "http://www.shuquge.com/txt/8659/" + str(url) |
18 | new_response = requests.get(str(new_url)) |
19 | new_response.encoding = new_response.apparent_encoding |
20 | html = new_response.text |
21 | result1 = re.findall('<div id="content" class="showtxt">(.*?)</div>', html, re.S) |
22 | with open('C:/Users/HP/Desktop/寒假辛酸/python爬虫/01 爬虫基础/作业/课堂案例/1、《剑来》爬取/剑来/' + name + ".txt", mode="w", |
23 | encoding="utf-8") as f: |
24 | f.write(str(result1[0]).replace("<br/> ", "").replace("<br/>", "")) |
25 | print(str(name) + '下载完毕!') |
26 | f.close() |
27 | shuquge_novel_download('http://www.shuquge.com/txt/8659/index.html') |
修改后代码,阅读起来舒服一点!

