概述:
大陆的用户都知道,我们的电视频道是搜不到港澳台地区的电视节目的,像经典的凤凰卫视,香港中文~~
为了满足观看我之前视频的一个粉丝的需要,现分享一下大陆地区港澳台的直播源的获取(不需翻墙~),顺便分享一个神一般存在的windows下视频播放软件。
最后呢,介绍一下几个强大好用的电视盒子(今年正月初一给爸妈的网络电视上装了,很好用!)
文章的最后,分享一下爬取的几个小案例(demo)港澳台地区直播源+精品电视盒子推荐+windows下神级视频播放软件!
1、前言:
1 | 今天,lures失眠了,写这篇文章时,北京时间是:2020年2月14号2:19,躺在床上半小时完全没有睡意,想打开电脑继续爬虫~~我也不知道是为什么! |
2 | 熟练的打开手机,连上老王VPN,打开youtube,看到了伙伴们对我的留言,说是要我分享一下港澳台地区直播源,想到之前自己在微信公众号上也写过一篇文章,于是就有了这篇文章的存在! |
3 | |
4 | 还有,其实,今天打开youtube时发现一个登陆不了的问题,后来发现是cookie数据没有清理导致的,果然,按照操作,把历史记录全部清理掉之后,就可以登录上去了,遇到相似问题的小伙伴们也不要惊慌,担心自己的ip被找到了,担心自己的电脑被黑了~~放心,Don't worry! Nothing is serious! |

2、windows下神级视频播放软件——Potplayer:
1 | 这个Potplayer,我其实在微信公众号上分享过了,文章链接是:https://mp.weixin.qq.com/s?__biz=MzU5OTkzNDMyMQ==&mid=2247484178&idx=1&sn=694addaf5ac503d624e278bf8a22508c&chksm=feac170cc9db9e1af772d5c32583bb2349530a2737581c21ec0a028817f90b3b0864744498c3&token=781344832&lang=zh_CN#rd |
1 | potplayer优点: |
2 | PotPlayer是KMPlayer原作者姜勇囍进入新公司Daum之后推出的,继承了 KMPlayer 所有的优点,拥有异常强大的内置音视频解码器,可以支持几乎全部音乐、视频文件格式的播放。采用 VC++ 进行了全面重构,并且原生支持64位操作系统,使得 PotPlayer 在 Windows 10 等新系统上,无论性能、兼容性和稳定性上的表现均比 KMP 要好不少;硬件加速、流畅优秀的全高清视频播放效果、强大的选项、滤镜、外挂式管理、DXVA等硬件解码;以及非常丰富且强大的设置选项,被誉为Win平台上最优秀的免费影音全能格式播放器。 |
3 | 由于 PotPlayer 内置了非常全面且兼容性良好的视频音频解码器,因此用户无需进行任何手动配置,即可以直接播放几乎目前网络上所有主流的视频音频格式文件,非常方便。而且它的界面也非常简洁清爽,PotPlayer 的配置选项非常丰富,各种功能也非常强大,对字幕文件的支持也非常好。在开启了 PotPlayer 的硬件解码支持之后,你一定会惊叹于它的内存占用率和播放效果! |

1 | 官网下载地址: |
2 | http://www.potplayercn.com/download/ |
3 | 我建议你们下PotPlayer1.7.18958 目前最后一个没有广告的版本,毕竟版本之间差异不是很大~~ |
1 | 关键是: |
2 | Potplayer操作也很简单啊,你只要把视频往里面一拖就能播放,而且播放速度可以一直往上加,应该到10左右吧!这一点应该就远超同类软件了吧!更重要的功能在后面,能加载港澳台地区的直播源!!! |
3、港澳台直播源:
1 | 其实,直播源的获取在网上能找到好多,只需要你输入关键词:potplayer直播源,然后就能获取 |
2 | 我就来分享两个吧:(我自己也在用的) |
3 | http://www.sharerw.com/a/jingyan/185.html |
4 | https://www.maxiaobang.com/2228.html |
5 | 近10000个频道,包含国内外及港澳台地区~~~应该够你用的了吧! |
6 | 操作方法在链接里面的文章都有! |
7 | |
8 | |
9 | 缺陷就是: |
10 | 有些直播源可能长时间没有更新了,所以播放不了,这时候你可以鼠标右键点击播放不了的电视台,选择移除 |
11 | 也可以网上寻找最新的直播源~~ |
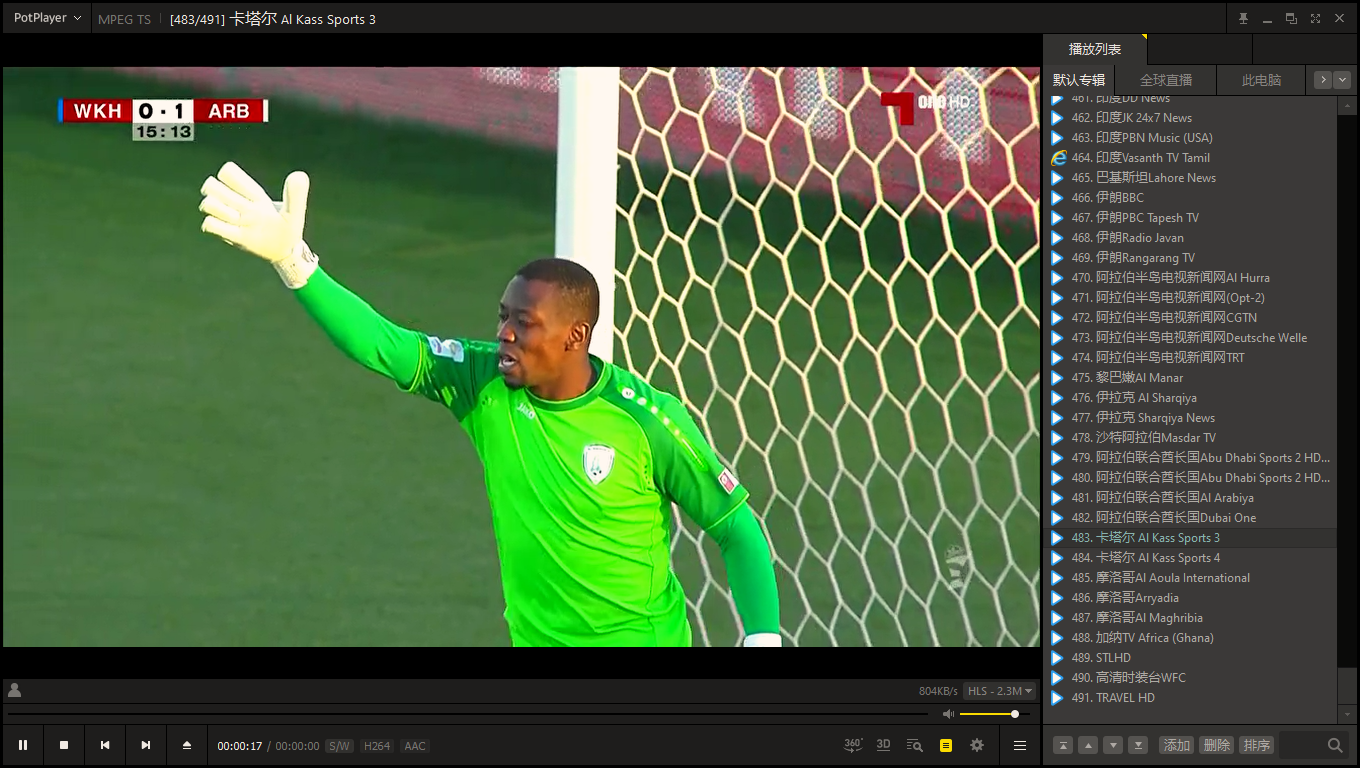
4、精品电视盒子的推荐:
1 | 年后干了一件特别尴尬的事,就是刚分享完一个电视盒子叫叶子TV,然后它就gg了,后来也不知道情况怎么样,今天来分享的电视盒子叫:小南TV,亿家直播港澳台版 |
2 | 地址:http://www.sharerw.com/a/ziyuan/385.html |
3 | 地址:http://www.sharerw.com/a/ziyuan/377.html |
4 | 也是分享者里面的,这个网站其实包含很多生活方面需要的资源,大家可以进去瞧瞧~~ |

5、最后:
1 | 有问题,可以在视频下方留言,有什么需要也可以再下方说,我会在闲余时间尽力的去找。 |
2 | 微信公众号:【空谷小莜蓝】,欢迎大家关注,有问题也可以进群讨论!感谢大家的观看和支持,愿你们的生活天天愉快! |

6、爬虫小案例:
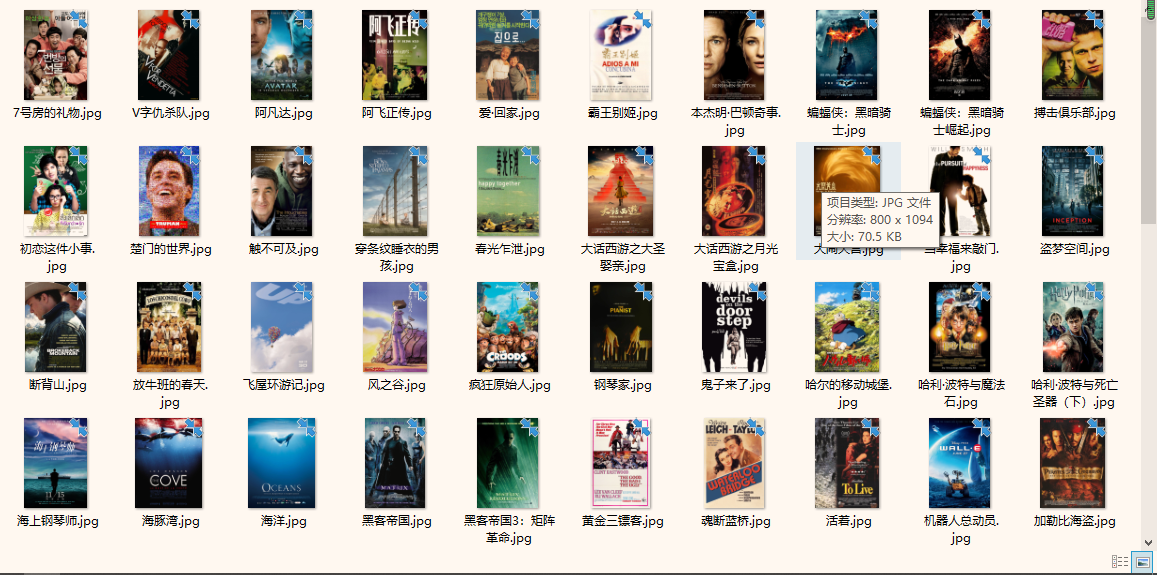
1、猫眼100详细信息及电影海报下载:
1 | """ |
2 | 使用 正则表达式 将猫眼 100 的全部电影信息全部提取出来。 |
3 | 目标网址:https://maoyan.com/board/4?offset=90 |
4 | name(电影名) |
5 | star(主演) |
6 | releasetime(上映时间) |
7 | score(评分) |
8 | """ |
9 | import requests |
10 | import re,csv,time,os |
11 | |
12 | def get_urls(url,page): |
13 | headers = { |
14 | 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', |
15 | 'Accept-Encoding': 'gzip, deflate, br', |
16 | 'Accept-Language': 'zh-CN,zh;q=0.9', |
17 | 'Cache-Control': 'max-age=0', |
18 | 'Connection': 'keep-alive', |
19 | 'Cookie': '__mta=217824553.1581516932611.1581518896582.1581595824574.9; uuid_n_v=v1; uuid=145CFAE04DA211EABB808B834CE4D9379E851BCB356B43C28E04A098DF5C6290; _lx_utm=utm_source%3Dgoogle%26utm_medium%3Dorganic; _lxsdk_cuid=17039c1088ec8-0e4043d3254989-376b4502-ff000-17039c1088ec8; _lxsdk=145CFAE04DA211EABB808B834CE4D9379E851BCB356B43C28E04A098DF5C6290; mojo-uuid=130983287367c85f4f7bf41ce4d4be2c; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1581516916,1581595824; _csrf=379e2970a39b347d40d116184163d57367c90685069c2f5ba1b1e04241e7cb4c; mojo-session-id={"id":"df9e49d6c8a16722af03f757831009be","time":1581606973033}; mojo-trace-id=1; _lxsdk_s=1703f1f3e19-fea-c97-565%7C%7C2', |
20 | 'Host': 'maoyan.com', |
21 | 'Sec-Fetch-Mode': 'navigate', |
22 | 'Sec-Fetch-Site': 'none', |
23 | 'Sec-Fetch-User': '?1', |
24 | 'Upgrade-Insecure-Requests': '1', |
25 | 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' |
26 | } |
27 | json = { |
28 | 'offset': str(10*page) |
29 | } |
30 | response = requests.get(url, headers=headers,data=json) |
31 | response.encoding = response.apparent_encoding |
32 | html = response.text |
33 | score = [] |
34 | star = re.findall('<p class="star">(.*?)</p>', html, re.S) |
35 | releasetime = re.findall('<p class="releasetime">(.*?)</p>',html,re.S) |
36 | scores = re.findall('<p class="score"><i class="integer">(.*?)</i><i class="fraction">([0-9])</i></p>',html,re.S) |
37 | message = re.findall('<img data-src="(.*?)" alt="(.*?)" class="board-img" />',html,re.S) |
38 | name = [] |
39 | image_url = [] |
40 | for i in range(len(message)): |
41 | name.append(message[i][1]) |
42 | image_url.append(str(message[i][0]).split(r'@')[0]) |
43 | for x,y in scores: |
44 | score.append(x+y) |
45 | path = '猫眼100电影照片' |
46 | if not os.path.exists(path): |
47 | os.mkdir(path) |
48 | for j in range(len(star)): |
49 | csv_write.writerow([name[j],str(star[j]).replace('\\n','').replace(r'主演:','').replace(' ',''),str(releasetime[j]).replace(r'上映时间:',''),score[j]]) |
50 | new_response = requests.get(image_url[j]) |
51 | new_response.encoding = new_response.apparent_encoding |
52 | with open(path + '/' + name[j] + '.jpg',mode="wb") as fp: |
53 | fp.write(new_response.content) |
54 | print(name[j] + '\t' + '图片下载完毕!') |
55 | fp.close() |
56 | |
57 | if __name__ == '__main__': |
58 | f = open('猫眼100电影信息爬取.csv',mode="a+",newline='',encoding="utf-8-sig") |
59 | csv_write = csv.writer(f) |
60 | csv_write.writerow(['电影名称','主演','上映时间','评分']) |
61 | for page in range(10): |
62 | url = 'https://maoyan.com/board/4?offset=' |
63 | url = url + str(10 * page) |
64 | get_urls(url,page) |
65 | print('第'+str(page+1)+'页信息爬取成功!') |
66 | f.close() |

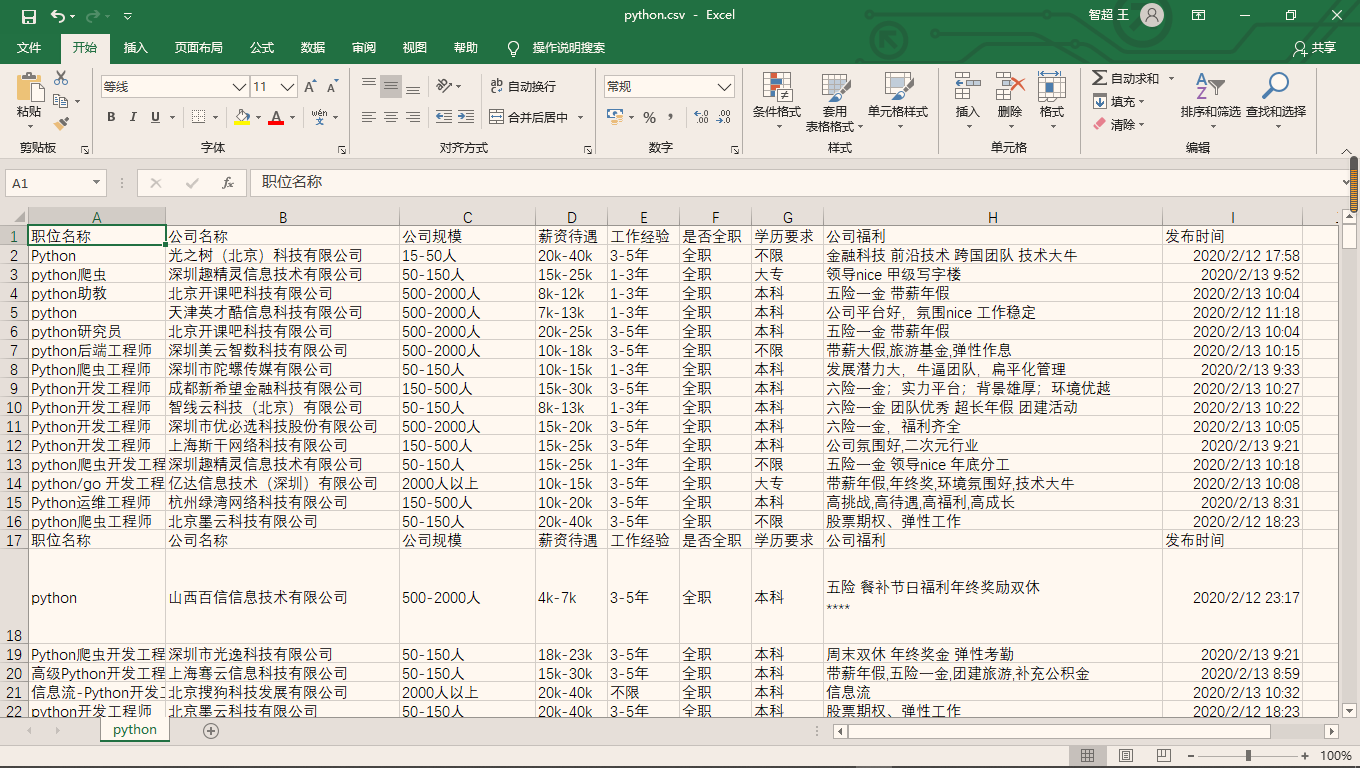
2、拉勾招聘信息爬取(输入关键词就可以爬虫相应职位)
1 | """ |
2 | 拉勾是一个典型的ajax异步加载的网站,我们需要找到它的真实url地址 |
3 | 在xhr接口那进行分析,真实的url地址,preview或response的时候会显示职位的信息 |
4 | """ |
5 | import requests |
6 | import csv,time |
7 | |
8 | url = 'https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false' |
9 | def get_cookie(): |
10 | cookie = requests.get('https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',headers={ |
11 | 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' |
12 | },allow_redirects=False).cookies |
13 | return cookie |
14 | |
15 | def put_into(page,kd): |
16 | headers = { |
17 | 'Host': 'www.lagou.com', |
18 | 'Origin': 'https://www.lagou.com', |
19 | 'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=', |
20 | 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' |
21 | } |
22 | json = { |
23 | 'first': 'true', |
24 | 'pn': str(page), |
25 | 'kd': str(kd) |
26 | } |
27 | response = requests.post(url=url, headers=headers, data=json, cookies=get_cookie()) |
28 | response.encoding = response.apparent_encoding |
29 | html = response.json()['content']['positionResult']['result'] |
30 | savedata(html,kd) |
31 | |
32 | def savedata(html,kd): |
33 | f = open(kd + '.csv', mode="a+",newline='',encoding='utf-8-sig') |
34 | csv_write = csv.writer(f) |
35 | csv_write.writerow(['职位名称', '公司名称', '公司规模', '薪资待遇', '工作经验', '是否全职', '学历要求', '公司福利', '发布时间']) |
36 | for i in range(len(html)): |
37 | positionName = html[i]['positionName'] # 职位名称 |
38 | companyFullName = html[i]['companyFullName'] # 公司名称 |
39 | companySize = html[i]['companySize'] # 公司规模 |
40 | salary = html[i]['salary'] # 薪资待遇 |
41 | workYear = html[i]['workYear'] # 工作经验 |
42 | jobNature = html[i]['jobNature'] # 是否全职 |
43 | education = html[i]['education'] # 学历要求 |
44 | positionAdvantage = html[i]['positionAdvantage'] # 公司福利 |
45 | lastLogin = html[i]['lastLogin'] # 发布时间 |
46 | # print(positionName,companyFullName,companySize,salary,workYear,jobNature,education,positionAdvantage,lastLogin) |
47 | csv_write.writerow([positionName, companyFullName, companySize, salary, workYear, jobNature, education, positionAdvantage,lastLogin]) |
48 | f.close() |
49 | |
50 | if __name__ == '__main__': |
51 | kd = str(input('请输入您想爬取的职业方向的关键词:')) |
52 | for page in range(2,31): |
53 | put_into(page,kd) |
54 | print('第'+str(page-1)+'页爬取成功!') |
55 | time.sleep(2) |
3、梨视频首页所有视频爬取:
1 | """ |
2 | 使用python请求此页面:https://www.pearvideo.com/video_1639869 将在获取的文本中会有下面这段内容 |
3 | |
4 | var contId="1639869",liveStatusUrl="liveStatus.jsp",liveSta="",playSta="1",autoPlay=!1,isLiving=!1,isVrVideo=!1,hdflvUrl="",sdflvUrl="",hdUrl="",sdUrl="",ldUrl="",srcUrl="https://video.pearvideo.com/mp4/adshort/20200107/cont-1639869-14773063_adpkg-ad_hd.mp4",vdoUrl=srcUrl,skinRes="//www.pearvideo.com/domain/skin",videoCDN="//video.pearvideo.com"; |
5 | var player; |
6 | |
7 | 请将其中的视频连接提取出来,并将视频下载到本地。视频名为页面的标题 |
8 | """ |
9 | import requests |
10 | import re,os,time |
11 | |
12 | def get_urls(url): |
13 | response = requests.get(url) |
14 | response.encoding = response.apparent_encoding |
15 | html = response.text |
16 | title = re.findall(' <img class="img" src="(.*?)" alt="(.*?)">',html,re.S)[0][1] |
17 | url = re.findall('srcUrl="(.*?)"',html,re.S)[0] |
18 | savevideo(title,url) |
19 | |
20 | def savevideo(title,url): |
21 | path = '梨视频' |
22 | if not os.path.exists(path): |
23 | os.mkdir(path) |
24 | response = requests.get(url) |
25 | with open(path + '/' + title + '.mp4',mode="wb") as f: |
26 | f.write(response.content) |
27 | f.close() |
28 | print(title +'\t'+'视频下载成功!') |
29 | |
30 | if __name__ == '__main__': |
31 | url = 'https://www.pearvideo.com/' |
32 | headers = { |
33 | 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3', |
34 | 'Accept-Encoding': 'gzip, deflate, br', |
35 | 'Accept-Language': 'zh-CN,zh;q=0.9', |
36 | 'Cache-Control': 'max-age=0', |
37 | 'Connection': 'keep-alive', |
38 | 'Cookie': '__secdyid=26be5460152fe9981e1bba3b584f9202a763407f4e406f3a021581581013; JSESSIONID=3CA57400AA62A2CE4B870332F6629670; PEAR_UUID=76cf720c-28f2-4d2a-aea5-7f1017607b93; PV_WWW=srv-pv-prod-portal2; _uab_collina=158158101560451013400154; p_h5_u=3CAE4F93-9F1A-4737-80D9-A55284F83B40; Hm_lvt_9707bc8d5f6bba210e7218b8496f076a=1581581021; UM_distinctid=1703d93345265d-0eb7f1cfdcd19a-376b4502-ff000-1703d933453558; CNZZDATA1260553744=1963143855-1581578442-%7C1581578442; __ads_session=okSGpyRObQl19BDHgAA=; Hm_lpvt_9707bc8d5f6bba210e7218b8496f076a=1581583728', |
39 | 'Host': 'www.pearvideo.com', |
40 | 'Referer': 'https://www.pearvideo.com/category_5', |
41 | 'Sec-Fetch-Mode': 'navigate', |
42 | 'Sec-Fetch-Site': 'same-origin', |
43 | 'Sec-Fetch-User': '?1', |
44 | 'Upgrade-Insecure-Requests': '1', |
45 | 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36' |
46 | } |
47 | response = requests.get(url, headers=headers) |
48 | html = response.text |
49 | result = re.findall('<div class="vervideo-bd">(.*?)</div>', html, re.S) |
50 | video_link = re.findall('<a href="(.*?)" class="vervideo-lilink actplay">', str(result), re.S) |
51 | video_title = re.findall('<div class="vervideo-title">(.*?)</div>', html, re.S) |
52 | for i in range(len(video_title)): |
53 | url = 'https://www.pearvideo.com/' + str(video_link[i]) |
54 | title = video_title[i] |
55 | get_urls(url) |
56 | time.sleep(2) |

