Blog47 全国大学生智能大赛【算法赛项】
算法赛项模拟试卷
1、一个顺序存储地线性表,设每个结点需占m个存储单元,假设第一个结点地地址为da1,那么第I个结点的地址为:
1 | 答案:da1 + (I - 1)*m |
*2、设有广义表D(a, b, D),其深度为:
1 | 答案:∞ |
3、在一棵二叉树上第5层的结点数最多是:
1 | 答案:16 |
4、在带有头节点的单链表HL中,要向表头插入一个由指针p指向的结点,则执行:
1 | 答案:p->next=HL->next;HL->next=p; |
*5、广义表A(a),那么表尾为:
1 | 答案:空表 |
6、栈和队列的共同特点是:
1 | 答案:只允许在端点处插入和删除 |
7、一个栈的入栈序列为a, b, c,那么出栈序列不可能是:
1 | 答案:c, a, b |
8、设有两个串t和p,求p在t中首次出现的位置的运算叫做:
1 | 答案:模式匹配 |
9、设有一个递归算法如下:
1 | int fact(int n){ |
下面正确的表达是:
1 | 答案:以上结论都不对 |
*10、AOV网是一种:
1 | 答案:有向无环图 |
11、在数据构造的讨论中把数据构造从逻辑上分为:
1 | 答案:线性结构和非线性结构 |
12、栈的数组表示中,top为栈顶指针,栈空的条件是:
1 | 答案:top = -1 |
13、假定一个顺序存储的循环队列的队头和对尾指针分别为f和r,那么判断队空的条件为:
1 | 答案:f == r |
14、算法分析的目的是:
1 | 答案:分析算法的效率以求改良 |
*15、设单循环链表中结点的构造为[data, link],且rear是指向非空的带表头结点的单循环链表的尾结点的指针。假设想删除链表第一个结点,那么应执行以下哪一个操作:
1 | 答案:s = rear;rear = rear->link;delete s; |
16、下面程序段的时间复杂度为:
1 | int f(unsigned int n){ |
1 | 答案:O(n!) |
17、顺序搜索算法适合于存储构造为【】的线性表:
1 | 答案:顺序存储或存储 |
18、算法一般都可以用哪几种控制结构组合而成:
1 | 答案:顺序、选择、循环 |
19、试问计算x(x(8))需要计算【】次x函数:
1 | int x(int n){ |
1 | 答案:9次 |

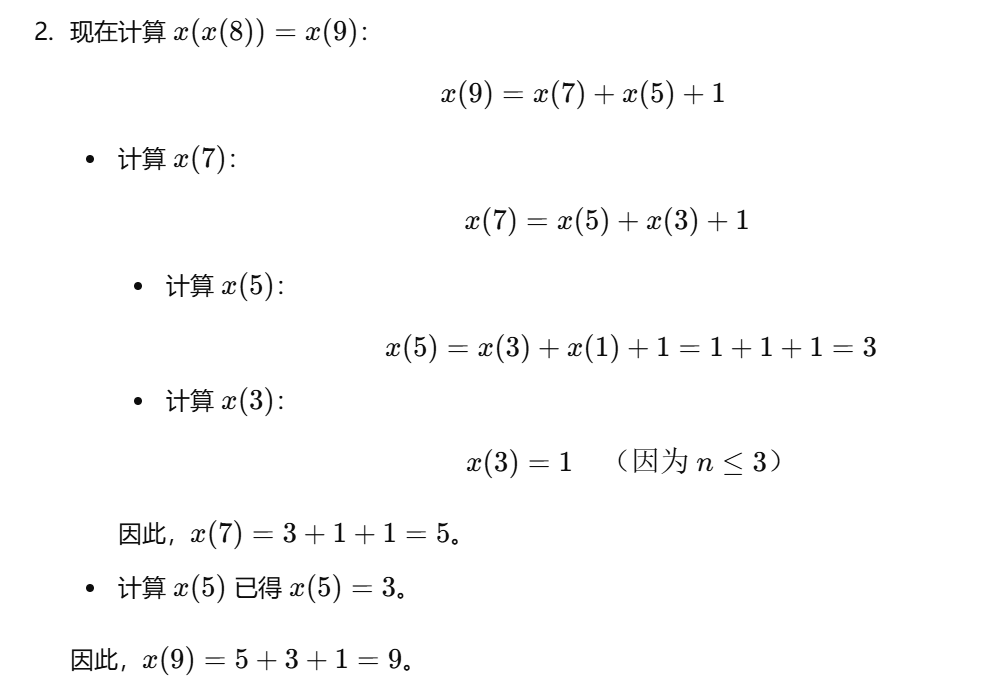
*20、对于一个具有n个顶点和e条边的无向图,进展拓扑排序时,总的时间为:
1 | 答案:n+e |
21、将一个递归算法改为对应的非递归算法时,通常需要使用:
1 | 答案:栈 |
*22、判断一个有向图是否存在回路,除了可以利用拓扑排序方法外,还可以利用:
1 | 答案:深度优先遍历算法 |
23、在数组A种,每一个数组元素A[i][j]占用3个存储字,行下标i从1到8,列下标j从1到10。所有数组元素相继存放于一个连续的存储空间中,那么存放该数组至少需要的存储字数是:
1 | 答案:240 |
24、在循环队列中用数组A[0...m-1]存放队列元素,其队头和队尾指针分别为front和rear,那么当前队列中的元素个数是:
1 | 答案:(rear - front + 1) % m |
25、如果想在4092个数据中只需要选择其中最小的5个,采用【】方法最好:
1 | 答案:堆排序 |
26、采用线性链表表示一个向量时,要求占用的存储空间地址:
1 | 答案:可连续可不连续 |
27、设单链表中结点构造为(data, link),指针q所指结点是指针p所指结点的直接前驱,假设在*q与*p之间插入结点*s,那么应指向以下哪一个操作:
1 | 答案:s->link = p->link;p->link = s; |
28、采用顺序搜索方法查找长度为n的顺序表时,搜索成功的平均搜索长度为:
1 | 答案:(n + 1)/2 |
29、递归表、再入表、纯表、线性表之间的关系为:
1 | 答案:递归表 > 再入表 > 纯表 > 线性表 |
30、二维数组是其数组元素为线性表的线性表【√】
1 | 解析: |
31、线性表的顺序存储构造的特点是逻辑关系上相邻的两个元素在物理位置上也相邻【√】
*32、任一棵二叉搜索树的平均搜索时间都小于用顺序搜索法搜索同样结点的顺序表的平均搜索时间【√】
1 | 二叉搜索树在平均情况下,查找效率高于顺序搜索表 |
33、二叉排序树可以是一棵空树【√】
*34、带权连通图的最小生成树的权值之和一定小于它的其它生成树的权值之和【√】
1 | 最小生成树是指权值之和最小的生成树 |
35、n个结点的有向图,假设它有n(n-1)条边,那么它一定是强连通的【×】
1 | 即使有n(n-1)条边,也不一定是强连通的,需要确保每个结点都能通过有向路径到达其他结点 |
36、空串与由空格组成的串没有区别【×】
1 | 空串是长度为0的字符串,而由空格组成的字符串是包含一个或多个空格字符的串,它们在计算机中是不同的 |
37、从逻辑关系上讲,数据构造主要分为两大类:线性构造和非线性构造【√】
1 | 数据结构可以分为线性结构(入数组、链表)和非线性结构(如树、图) |
38、二叉树是树的一种特殊情况【√】
1 | 二叉树是树的特殊形式,每个结点最多由两个子结点 |
39、线性表的逻辑顺序与物理顺序总是一致的【×】
1 | 在线性表的顺序存储结构中,逻辑顺序与物理顺序一致,但在链式存储结构中,逻辑顺序和物理存储位置可能并不一致 |
*40、矩阵连乘问题的算法可由【】设计实现
1 | 动态规划 |
*41、在稀疏矩阵的带行指针向量的链接存储中,每个单链表中的结点都具有相同的【】
1 | 列号 |
*42、使用回溯法进行状态空间树裁剪分支时一般有两个标准:约束标准和目标函数的界,N皇后问题和0/1背包问题正好是两种不同的类型,其中同时使用约束条件和目标函数的界进行裁剪的是【】
1 | 0/1背包问题 |
*43、拉斯维加斯算法找到的解一定是【】
1 | 正确 |
44、算法的空间复杂度指的是算法运行所需的【】
1 | 辅助存储空间 |
45、栈是一种【】的数据结构
1 | 线性/后进先出 |
46、从二叉搜索树中查找一个元素时,其时间复杂度大致为【】
47、快速排序在最坏情况下的时间复杂度为【】
*48、以广度优先或以最小耗费方式搜索问题解的算法称为【】
1 | 分支限界法 |
49、【】是贪心算法可行的第一个基本要素,也是贪心算法与动态规划算法的主要区别
1 | 最优子结构/贪心选择性质 |
 微信
微信- 支付宝